Multiprocessing boosts CPU-bound tasks with true parallelism, while multithreading shines in I/O-bound workloads despite the GIL.
Python Multiprocessing vs. Multithreading: How to Balance Speed, Cost, and Complexity
Published on: 17 December 2025
Last updated on: 16 June 2026

Python multiprocessing vs multithreading:
Running multiple tasks at once sounds simple in theory.
In Python, you can do it with multithreading or multiprocessing.
Both aim to make your application faster, but they approach the problem from two completely different angles.
Think of it like teamwork.
Multithreading is everyone working together in the same office, sharing the same space and resources.
Multiprocessing is when you open several offices and let teams work independently in parallel.
Choosing between the two isn’t just a coding decision—it shapes how your app scales, how efficiently it uses CPU power, and even how much you’ll pay for cloud infrastructure.
In this guide, we’ll unpack how both models work, where each one excels, and how to choose the right fit for your workload and budget.
Why This Debate Still Matters in 2025
You’ve just deployed a new analytics feature. It works great in testing, but as real users start hitting it, response times spike and CPU usage goes through the roof.
Your team scrambles to fix it by caching, refactoring, even throwing in more servers but nothing quite works.
That’s when the question comes up: Is the problem in our code or the way we’re running it?
This is where the multiprocessing vs. multithreading debate really begins.
Both can make Python run multiple tasks at once, but the wrong choice can quietly drain resources, inflate cloud costs, and slow everything down under scale.
In 2025, this isn’t just a developer argument anymore, it’s an operational strategy.
With Python 3.13 introducing free-threaded builds and teams shifting to distributed systems, choosing the right concurrency model is now part of building sustainable, scalable software.
This article breaks down how multiprocessing and multithreading really work, where each makes sense, and how to pick the one that keeps your Python projects fast, efficient, and scalable.
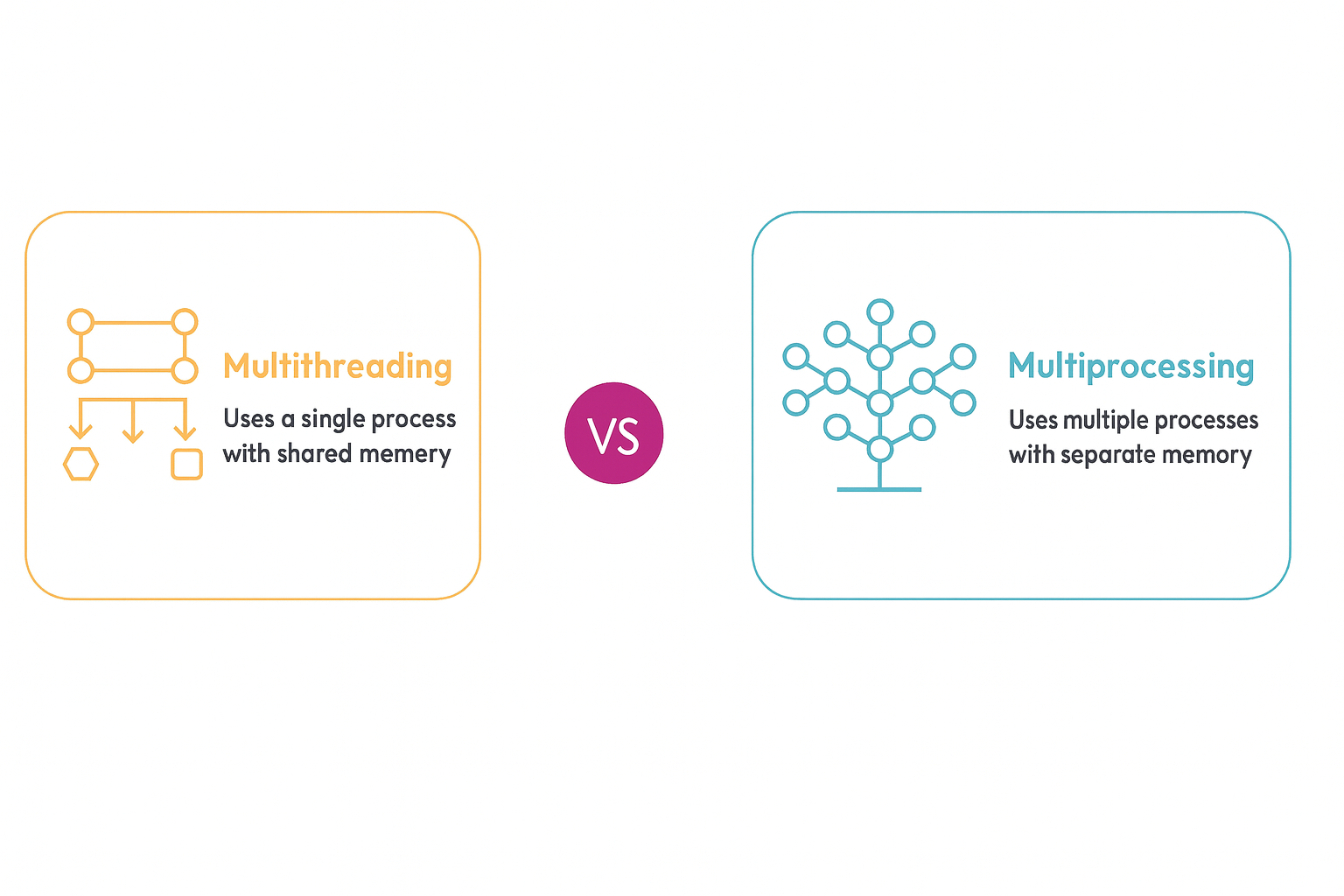
Multiprocessing vs. Multithreading: The Core Difference
Both techniques let you perform multiple operations at once, but they work differently.
|
Factor |
Multithreading |
Multiprocessing |
|
Memory |
Shared within one process |
Isolated per process |
|
Parallelism |
Limited by GIL |
True parallel execution |
|
Best For |
I/O-bound workloads |
CPU-bound workloads |
|
Overhead |
Lightweight and fast |
Higher memory and startup cost |
|
APIs |
threading, ThreadPoolExecutor |
multiprocessing, ProcessPoolExecutor |
Threads live inside the same process and share memory. That makes them efficient but vulnerable to race conditions. Python’s Global Interpreter Lock (GIL) also prevents true parallel execution of threads, which limits CPU performance.
Processes, on the other hand, each have their own interpreter and memory space. They can run on different cores, achieving real parallelism, but at the cost of more memory and slower startup.
Identify Your Workload: CPU-Bound or I/O-Bound
You don’t need guesswork. You need context.
|
Workload |
Recommended Model |
Why |
|
API handling, file I/O, web scraping |
Multithreading |
Manages waiting efficiently |
|
Data processing, ML training, analytics |
Multiprocessing |
Utilizes multiple cores fully |
|
Network servers, async microservices |
Async I/O |
High concurrency, low overhead |
|
Hybrid workloads |
Combination |
Balances CPU and I/O load |
Run small tests before committing. Compare throughput, CPU load, and memory use between both models. The right answer depends not only on speed, but also on scalability and cost efficiency.
.jpg)
Real-World Code Comparison
Let’s look at a simple example of each model.
Multithreading Example
import threading
import requests
def fetch(url):
requests.get(url)
urls = ["https://example.com"] * 10
threads = [threading.Thread(target=fetch, args=(u,)) for u in urls]
for t in threads:
t.start()
for t in threads:
t.join()
Best for: I/O-heavy workloads like file downloads or API calls.
Limitation: Only one thread executes Python code at a time because of the GIL.
Multiprocessing Example
from multiprocessing import Pool
def compute(x):
return sum(i * i for i in range(x))
with Pool() as p:
results = p.map(compute, [10_000_000] * 8)
Best for: CPU-intensive tasks like number crunching or machine learning.
Limitation: Each process uses its own memory, so overhead grows quickly.
Cost and Performance Optimization
Performance always comes at a cost. The trick is finding the sweet spot.
Threads:
- Start fast, use less memory.
- Don’t help much with pure computation.
Processes:
- Run in true parallel.
- Consume more RAM and take longer to start.
If you’re scaling in the cloud, each new process can duplicate your app’s memory footprint. Multiply that by dozens of workers, and you might see costs climb fast.
To optimize:
- Use shared memory for large data chunks.
- Batch smaller tasks to reduce process overhead.
- Track memory per worker and CPU utilization per node before scaling horizontally.
Smart teams treat concurrency like a budget. Every thread or process should earn its keep.
Debugging and Risk Management
Parallelism sounds cool until something breaks.
Here’s what to watch for:
Threading Pitfalls
- Race conditions if two threads modify shared data.
- Deadlocks when locks wait on each other.
- Unpredictable bugs that appear under load.
Use locks (threading.Lock), immutable data, or thread-safe queues to avoid chaos.
Multiprocessing Pitfalls
- Large objects are expensive to transfer between processes.
- Some objects can’t be pickled and will crash silently.
- The wrong start method (fork on macOS) can break compatibility.
Test your code with smaller workloads before scaling up. Use faulthandler and concurrent.futures with timeouts to catch deadlocks and hung workers early.
Monitoring and Operability
The real test of concurrency isn’t just performance. It’s predictability.
Track metrics that tie directly to your service goals:
- CPU utilization per core
- Memory per worker
- p95 latency
- Throughput
- Queue depth
Use Prometheus, Grafana, or New Relic for visualization.
Set clear SLOs. For example:
- Keep p95 latency below 300 ms.
- Maintain CPU under 85%.
- Limit memory per worker to 300 MB.
Monitoring keeps you honest. It turns performance experiments into operational reliability.
The Future: No-GIL Python and Beyond
Python is changing fast.
With version 3.13, optional free-threaded builds are available that remove the GIL entirely. These builds finally allow true parallel threads, but at the cost of around 40% slower single-thread performance.
Python 3.14 also changes the default multiprocessing start method to forkserver, which improves stability across different platforms. However, it can slightly increase startup time and memory usage.
What does this mean for you?
Concurrency decisions are no longer permanent. As the language evolves, design your systems with flexibility in mind so that upgrading Python won’t require rewriting everything.
The Big Picture
Here’s the short version:
- Threads are great for I/O.
- Processes are great for computation.
- Async I/O is perfect for scalable network services.
- Monitoring keeps you from overpaying for performance.
- Python’s future is moving toward true parallelism.
Concurrency isn’t just about making code faster. It’s about building systems that scale responsibly, control costs, and stay stable under real-world pressure.
In 2025, that’s what separates good engineering from great engineering.

I work at the point where product decisions, system architecture, and engineering execution meet. At Mediusware, I’m accountable for how technology choices affect reliability, scale, and long-term delivery for our clients.
Featureblogs
Relatedblogs
01
Integrating Redux with React: A Comprehensive Guide02
Laravel pagination and filtering with already loaded data as array in memory03
React + Three.js + React Three Fiber: Crafting Interactive 3D views in Web Applications04
Advanced Caching Strategies for Django Applications05
Implementing Roles and Permissions in Laravel Using Guard-Laravel