- Discover why most teams scale chaos, not clarity and how to fix it.
- Learn proven 2025 frameworks for automation, observability, and DevOps culture.
Why Scaling DevOps Feels Like Herding Cats
Published on: 6 January 2026
Last updated on: 16 June 2026

Scaling DevOps sounds simple until you actually try it.
You automate, standardize, and integrate and somehow, everything still feels harder.
Pipelines multiply, dashboards glow red, and every team swears their YAML is “the right one.”
Suddenly, you’re no longer deploying software. You’re herding cats… with CI/CD collars.
According to the 2024 Puppet State of DevOps Report, 66% of organizations report that automation is part of their platform engineering scope.
Yet, only a fraction describe their DevOps scaling as truly mature. The reason? Most scale chaos, not clarity.
What Scaling DevOps Really Means
Scaling DevOps is about expanding your processes, tools, and culture without losing velocity or control.
It’s not just more automation, it's smarter alignment between people, platforms, and pipelines. As Gene Kim author of The DevOps Handbook, explains,
DevOps isn’t about automation, just as astronomy isn’t about telescopes.
Automation can’t solve dysfunction, it only amplifies it.
Without shared ownership and accountability, even the best CI/CD stack becomes a bottleneck.
Automate Intelligently, Not Blindly

Automation is the heartbeat of DevOps, but too much of it, done poorly, becomes technical debt in disguise.
As Kelsey Hightower said:
The goal of automation isn't to eliminate people, it's to eliminate toil so people can focus on higher-value work.
If your pipeline breaks and no one understands why, that’s not efficiency, that’s fragility.
Where Smart Automation Starts
- Infrastructure as Code (IaC): Use Terraform or Pulumi for consistent provisioning.
- Config Management: Apply Ansible or Chef to standardize environments.
- Test Automation: Automate unit, integration, and regression tests early.
- Deployment Automation: Leverage ArgoCD or Spinnaker for GitOps-driven deployments.
- Rollback & Resilience: Always script your rollback plans; chaos testing isn’t optional anymore.
When teams automate with empathy like documenting, monitoring, and communicating every step, they scale sustainably.
Build CI/CD Pipelines That Actually Scale
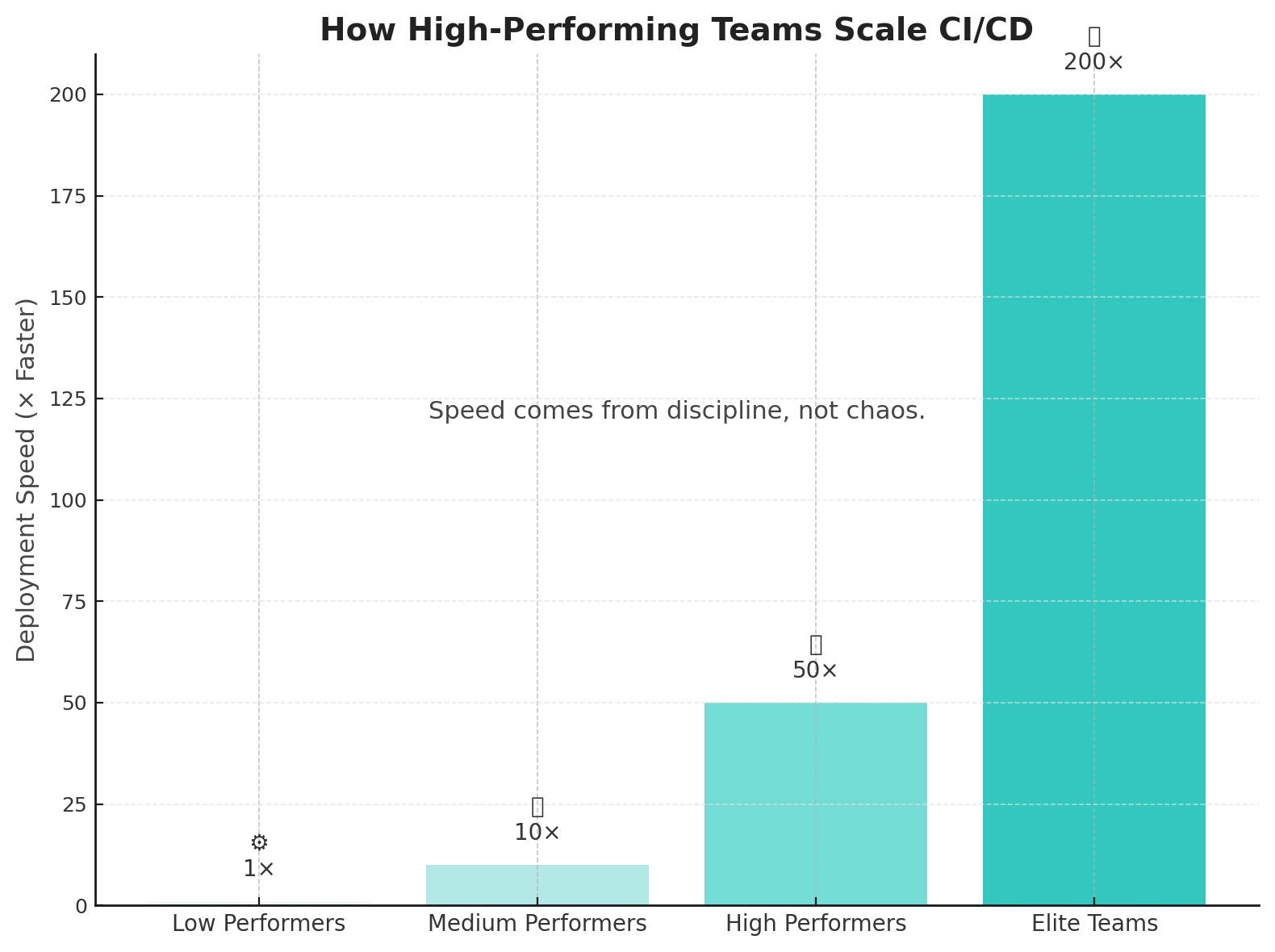
A fast pipeline is good. A reliable one is better.
Without a strong CI/CD foundation, scaling DevOps is like pouring water into a leaky bucket.
According to the 2024 DORA Report, elite DevOps performers deploy 182–208 times faster and recover 2,293 times quicker than low performers.
The difference isn’t tools, it’s discipline.
Best Practices for Scalable Pipelines:
- Adopt GitOps-first workflows: Let Git manage your deployment states.
- Containerize everything: Use Docker for consistency across environments.
- Deploy on Kubernetes: Orchestrate workloads efficiently.
- Use feature flags: Roll out changes gradually without redeploying.
- Apply canary or blue-green releases: Minimize downtime and reduce risk.
A healthy CI/CD pipeline doesn’t just automate, it teaches your organization to move fast without fear.
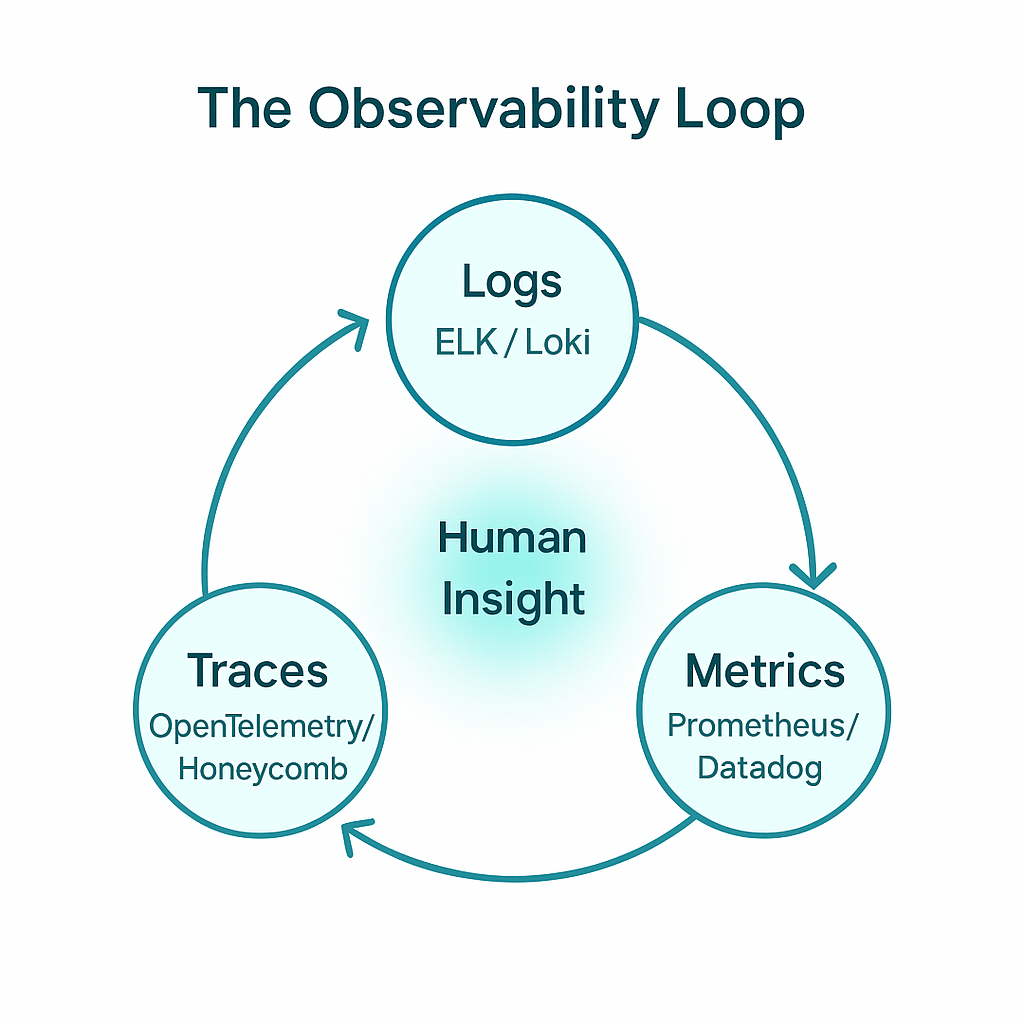
You can’t scale what you can’t see.
Metrics and logs are only half the story, observability tells you why something broke, not just what broke.
Charity Majors, co-founder of Honeycomb, says
"Observability is about giving humans the power to ask and answer questions about their systems, without shipping new code.”
It’s not about fancy dashboards, it’s about feedback loops that close fast.
How to Improve Observability
- Aggregate logs, metrics, and traces with Grafana, Prometheus, or Loki.
- Implement OpenTelemetry for full-stack visibility.
- Connect monitoring to incident response systems like PagerDuty or Opsgenie.
- Visualize trends to predict bottlenecks before they occur.
According to the Honeycomb 2024 Observability Report, teams with strong observability practices report 45% lower MTTR (Mean Time to Recovery).
Visibility is not a luxury, it’s insurance against chaos.
Build a Culture That Can Handle Scale
Tools can’t fix culture.
If your teams aren’t aligned, no Kubernetes cluster can save you.
DevOps was born as a cultural movement, and that foundation matters even more at scale.
Break down silos, share ownership, and focus on learning over blame.
As Jez Humble and the DORA team highlight, the highest-performing DevOps organizations balance speed and stability through collaboration and psychological safety.
Cultural Practices That Scale
- Blameless Postmortems: Turn failures into shared learning.
- SRE Mindset: Reduce toil, define clear SLOs, and measure reliability.
- Cross-functional Pods: Merge Dev, Ops, QA, and Security for faster decisions.
- Continuous Feedback: Build a rhythm of improvement into every sprint.
When people trust the system and each other, scaling becomes momentum, not mayhem.
Avoid These Common Scaling Traps
Overengineering
Not every problem needs Terraform, Helm, and three layers of YAML.
Start simple, scale what works, and expand when your product demands it.
Ignoring Security Early
Scaling DevOps without DevSecOps is a ticking time bomb.
Shift security left using automated scanning (Snyk, Trivy), secrets management (Vault), and role-based access control.
Tool Sprawl
Adding every “DevOps optimizer” tool will slow you down.
Focus on integration, not accumulation. A small, well-aligned toolchain beats a massive disconnected one.
No Measurement or Optimization
If you can’t measure, you can’t improve.
Monitor deployment frequency, MTTR, and incident rates, they’re your early-warning system for scale fatigue.
The Data Behind DevOps Scaling (2024–2025)
Here’s what recent research tells us about where DevOps stands today:
| Metric | Elite Teams | Low Performers | Source |
| Deployment Frequency | 182–208× faster | Baseline | DORA 2024 |
| Lead Time for Changes | 106× shorter | Baseline | Puppet 2024 |
| MTTR (Mean Time to Recovery) | 45% lower | Baseline | Honeycomb 2024 |
| Automation Adoption | 66% of orgs | - | Puppet 2024 |
| Observability Adoption | 58% of orgs | - | Honeycomb 2024 |
This data reinforces a clear truth: DevOps success at scale is cultural before it is technical.

The Big Picture: Scaling Without Losing Control
Scaling DevOps isn’t a milestone, it’s a moving target.
Technology will evolve, teams will grow, and your systems will always need rebalancing.
The organizations that thrive are those that:
- Automate with empathy, not ego.
- Invest in observability before incidents demand it.
- Treat culture as their highest-leverage infrastructure.
As Gene Kim once said,
“The Second Way is about creating constant feedback loops... so we can quickly detect and recover from failures, making failure safe, inexpensive, and routine.”
When your feedback loops are healthy, scaling stops feeling like herding cats and starts feeling like progress.
Build Systems That Scale with You
At Mediusware, we help fast-growing engineering teams scale DevOps with discipline, automation, and observability built for the future.
If your pipelines feel like chaos in motion, let’s fix that together.
Schedule a free consultation and turn DevOps from firefighting to forward motion.

I work at the point where product decisions, system architecture, and engineering execution meet. At Mediusware, I’m accountable for how technology choices affect reliability, scale, and long-term delivery for our clients.
Featureblogs
Relatedblogs
01
Top 10 Programming Languages to Use in 202402
Looking Ahead: Top 10 Software Development Trends for 202403
Top 20 Best Software Companies in Bangladesh (2024)04
7 Ways to Ensure Data Security When Outsourcing Software Development05
How to Create a Stunning WordPress Website in 2024: Step-by-Step TutorialAuthorblogs
01
How Digital Agencies Can Deliver Custom Software Without Hiring Developers02
AI in FinTech: Build, Buy, or Integrate? A Founder's Decision Framework03
The Real Reason SaaS MVPs Miss Launch Deadlines04
How Seed-Stage SaaS Teams Add Engineering Capacity Without Hiring Chaos05
Why Seed-Stage SaaS Startups Struggle to Ship Fast