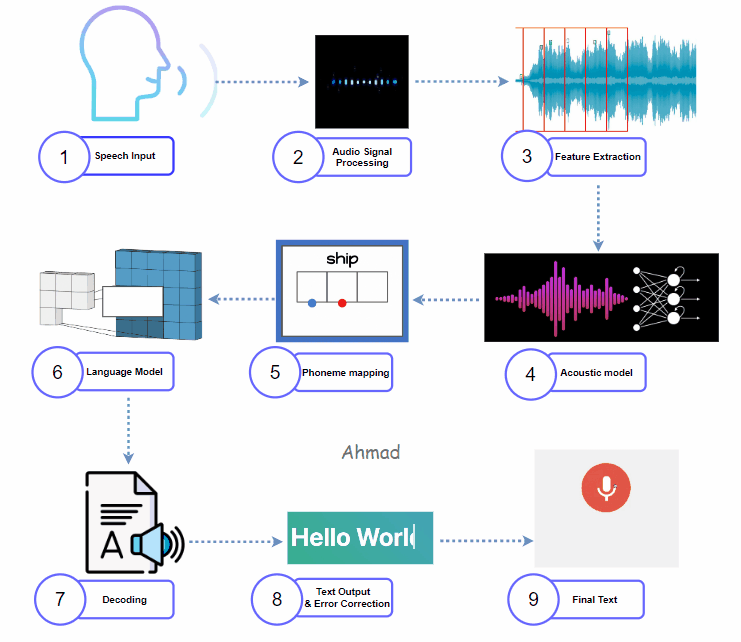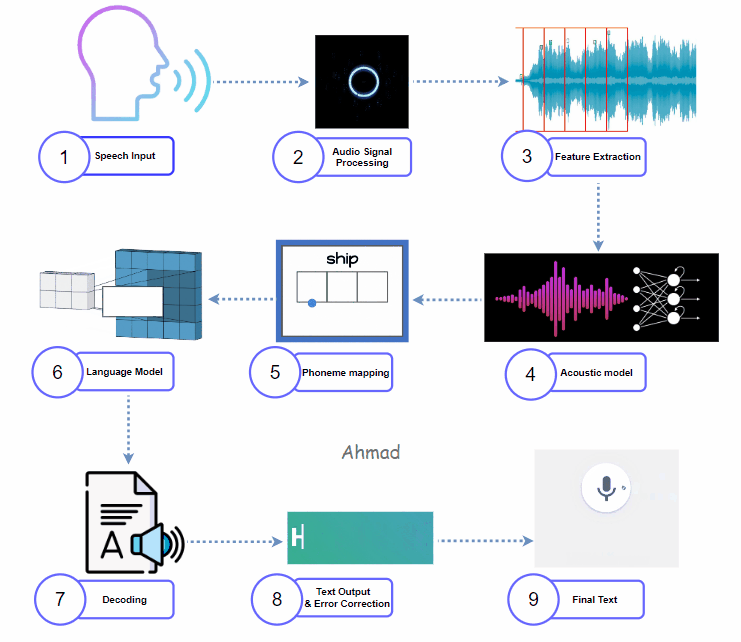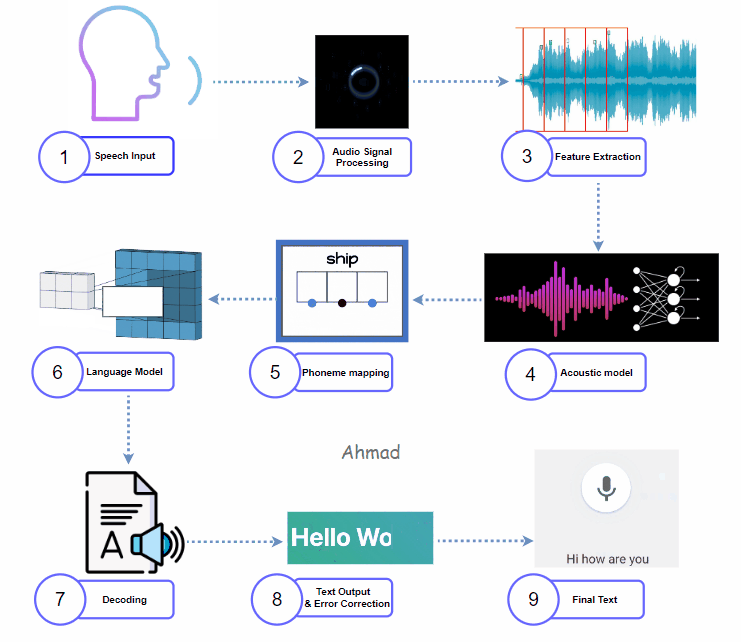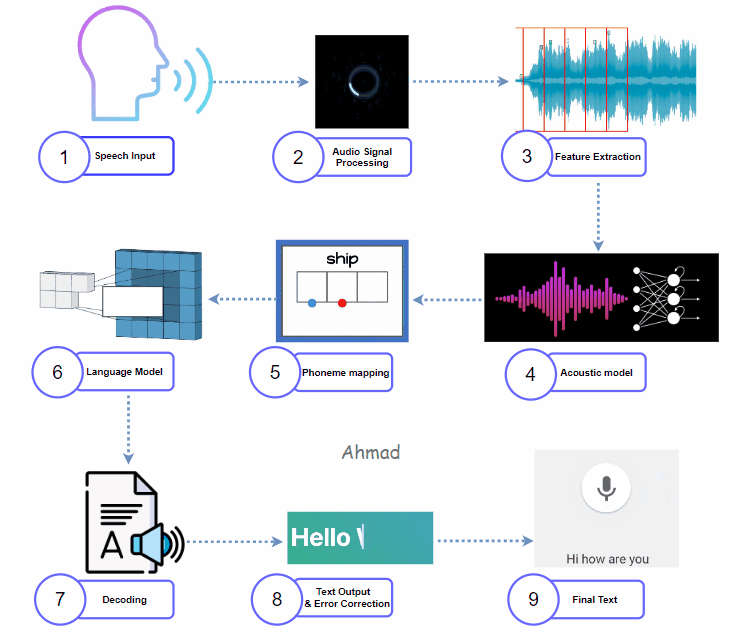
1. Capturing Speech Input:
It starts with the user interface. A microphone picks up audio as a waveform.
This waveform is unique to each speaker. It includes noise, distortions, and other features. Captured audio first goes through a process called analog-to-digital conversion. This changes it into a digital signal. This prepares the audio for further processing.
2. Audio Signal Processing:
Before the audio can be fed into a model, it must be cleaned and structured. Signal processing applies several transformations:
- Noise Reduction: Filtering algorithms reduce ambient noise and enhance the speaker's voice.
- Framing: The audio signal is split into smaller frames, usually lasting 20 to 40 milliseconds. This helps the model process the data more easily.
- Windowing and Overlapping: Overlapping windows smoothen transitions between frames to avoid abrupt changes in analysis, providing continuity for the model.
3. Feature Extraction:
Once processed, the model performs feature extraction, translating audio into a format that machines understand. Techniques like Mel-Frequency Cepstral Coefficients (MFCC) and Spectrograms help turn audio waveforms into visual images. These images show frequency and amplitude. The features extracted often include:
- Frequency: Determines pitch changes.
- Energy: Captures volume or loudness.
- Temporal Patterns: Maps out rhythm and emphasis in speech.
4. Acoustic Model:
The acoustic model is usually a deep learning model. It can be a Convolutional Neural Network (CNN) or a Recurrent Neural Network (RNN). This model processes features to identify phonemes, which are the smallest sound units. In a hybrid STT model, acoustic models mix traditional Hidden Markov Models (HMM) with neural networks. This combination improves phoneme prediction accuracy and processing efficiency. The model produces probability scores for each phoneme in the context of the language.
5. Phoneme Mapping:
The system then maps phonemes to actual words. This step uses a dictionary or lexicon to convert recognized phonemes into valid word candidates. Hybrid models utilize both rule-based approaches and statistical mapping to increase word prediction accuracy. The system also applies context-based constraints, eliminating improbable word combinations.
6. Language Model:
The language model (LM) refines the output by adding semantic and syntactic context. Utilizing N-grams, Recurrent Neural Networks (RNNs), or Transformer models, the LM considers sentence structure, grammar, and context, enabling it to resolve homophones and contextual word choices (e.g., “their” vs. “there”). This step is critical for applications like real-time translation and voice-activated commands, where context ensures coherence.
7. Decoding:
During decoding, the model combines outputs from the acoustic and language models. The model uses algorithms like the Viterbi algorithm or beam search. These help it find the best word sequences to create a clear sentence. Decoding is optimized to minimize latency, especially in real-time applications where low delay is essential.
8. Text Output & Error Correction:
After decoding, the raw text output may still contain minor errors. An error correction model or post-processing algorithm performs spell-checking, grammar correction, and contextual adjustments. This phase may use training data on common mistakes. This includes things like speaker accents and phrases that are often misheard. The goal is to improve the transcription.
9. Final Text Output:
The final output is the fully transcribed, error corrected text. This text can now be used in downstream applications, whether for subtitles, virtual assistant responses, or voice commands.